Original article: The York Gospels: a 1000-year biological palimpsest
Remember when we used to write on paper? Maybe you had a favourite notebook brand, or a preference for blank over ruled pages? A few hundred years back, scribes had a choice between calf, sheep, or goat skins (aka parchment) for their manuscript pages. Traditionally, book conservators, palaeographers, or the curious could identify the type of animal used to prepare a parchment by looking at the hair follicle patterns left on its surface. Today, in the day and age of personalised genome sequencing, Matthew Teasdale, Sarah Fiddyment, and a team of archaeologists, biologists, and conservators demonstrate a brilliant hack for unlocking a whole galaxy of information from medieval parchment manuscripts without so much as teasing out a single fibril from their skins.
Archival footage showing the parchment making process in England, 1939.
The group has deployed their revolutionary technique, eZooMS (eraser-based (triboelectric) ZooArchaeology by Mass Spectrometry), to study the York Gospels—an Anglo-Saxon gospel book dating back to 990 AD (and used to this day at York Minster) that contains the oaths sworn by deans, archdeacons, canons, and vicars choral. eZooMS is a non-destructive technique that uses the by-products of eraser-based cleaning to collect proteins and DNA from sensitive and precious documents (i.e., all ancient and medieval manuscripts) for analysis. During the routine cleaning of manuscripts, conservators use erasers to gently remove dust and soiling from the surface of each folio. The electrostatic charge generated by these synthetic (PVC) erasers is sufficient to pick up collagen and DNA from the parchment. The eraser shavings are collected and sent off for analysis.
After the collagen is stripped from the eraser debris, it is cut into smaller pieces (peptides) by enzymes. This soup of mixed protein chunks is analysed using mass spectrometry—a technique that can separate a complex mixture of molecules, classify them by size and quantity, and display the results as a mass spectrum. By comparing the mass spectrum of the unknown parchment peptides to databases of spectra from a variety of known contemporary and archaeological animal peptides, the biological origins of each folio can be revealed.
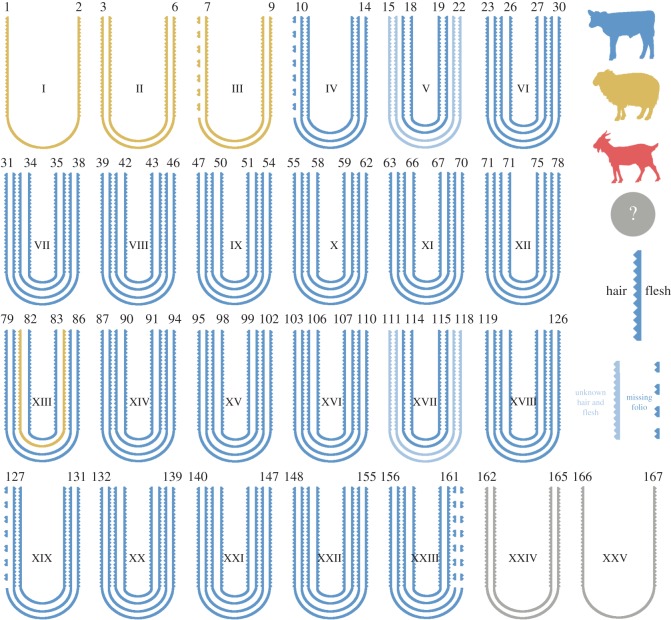
Figure 1. Structure of the quires comprising the manuscript, and species identification of the bifolia using eZooMS [figure and caption obtained from original article by Teasdale et al. 2017]
The researchers have gone one step further in their study of the York Gospels. They have managed to extract and sequence both the endogenous DNA from the animals whose skins formed the folios of the gospels (Figure 1) AND exogenous DNA from humans that have interacted with the manuscript. Finally, they’ve explored the ‘metagenome’ of the book by sequencing the microbiome residing on several of the folios, confirming a match to human skin, mouth, and nose microbes (from all that oath swearing and devotional kissing over the course of centuries). For the conservators in the room, a microbial precursor to the dreaded purple-spot disease of parchment was also detected (Saccharopolyspora), meaning that this simple, non-invasive method can be used as an early diagnostic tool for this degradation phenomenon.
The study not only answers some questions about the makeup and microbiome of the York Gospels, but also opens up many other avenues for research—both scientific and historical. The proteomic and genetic information revealed that many of the skins sampled belonged to (high value) female calves, that some of the oaths and deeds contained in the manuscript are written on sheep skins, and that most of the sampled skins could be geolocated within the European cattle diversity. With more sampling, databases might be built up which could help historians understand medieval animal trade and husbandry methods, material value, use, and re-use. On the surface of every folio of every manuscript lies a hidden library of genomic information ready to be sequenced and translated.
All figures reproduced from the original manuscript under CC-BY open access license.
